Chapter 12
Adaptive Optimization System
A comprehensive discussion of the design and implementation of the original Jikes RVM adaptive optimization system is given in the OOPSLA 2000 paper by Arnold, Fink, Grove, Hind and Sweeney. A number of aspects of the system have been changed since 2000, so a better resource is a technical report Nov. 2004 technical report that describes the architecture and implementation in some detail. This section of the userguide is based on section 5 of the 2004 technical report.
The implementation of the Jikes RVM adaptive optimization system uses a number of Java threads: several organizer threads in the runtime measurements component, the controller thread, and the compilation thread. The various threads are loosely coupled, communicating with each other through shared queues and/or the other in memory data structures. All queues in the system are blocking priority queues; if a consumer thread performs a dequeue operation when the queue is empty, it suspends until a producer thread performs an enqueue operation.
The adaptive optimization system performs two primary tasks: selective optimization and profile-directed inlining.
Selective Optimization The goal of selective optimization is to identify regions of code in which the application spends significant execution time (often called “hot spots”), determine if overall application performance is likely to be improved by further optimizing one or more hot spots, and if so to invoke the optimizing compiler and install the resulting optimized code in the virtual machine.
In Jikes RVM, the unit of optimization is a method. Thus, to perform selective optimization, first the runtime measurements component must identify candidate methods (“hot methods”) for the controller to consider. To this end, it installs a listener that periodically samples the currently executing method at every taken yieldpoint. When it is time to take a sample, the listener inspects the thread’s call stack and records a single compiled method id into a buffer. If the yieldpoint occurs in the prologue of a method, then the listener additionally records the compiled method id of the current activation’s caller. If the taken yieldpoint occurs on a loop backedge or method epilogue, then the listener records the compiled method id of the current method.
When the buffer of samples is full, the sampling window ends. The listener then unregisters itself (stops taking samples) and wakes the sleeping Hot Method Organizer. The Hot Method Organizer processes the buffer of compiled method ids by updating the Method Sample Data. This data structure maintains, for every compiled method, the total number of times that it has been sampled. Careful design of this data structure (MethodCountData.java) was critical to achieving low profiling overhead. In addition to supporting lookups and updates by compiled method id, it must also efficiently enumerate all methods that have been sampled more times than a (varying) threshold value. After updating the Method Sample Data, the Hot Method Organizer creates an event for each method that has been sampled in this window and adds it to the controller’s priority queue, using the sample value as its priority. The event contains the compiled method and the total number of times it has been sampled since the beginning of execution. After enqueuing the last event, the Hot Method Organizer re-registers the method listener and then sleeps until the next buffer of samples is ready to be processed.
When the priority queue delivers an event to the controller, the controller dequeues the event and applies the model-driven recompilation policy to determine what action (if any) to take for the indicated method. If the controller decides to recompile the method, it creates a recompilation event that describes the method to be compiled and the optimization plan to use and places it on the recompilation queue. The recompilation queue prioritizes events based on the cost-benefit computation.
When an event is available on the recompilation queue, the recompilation thread removes it and performs the compilation activity specified by the event. It invokes the optimizing compiler at the specified optimization level and installs the resulting compiled method into the VM.
Although the overall structure of selective optimization in Jikes RVM is similar to that originally described in Arnold et al’s OOPSLA 2000 paper, we have made several changes and improvements based on further experience with the system. The most significant change is that in the previous system, the method sample organizer attempted to filter the set of methods it presented to the controller. The organizer passed along to the controller only methods considered ”hot”. The organizer deemed a method ”hot” if the percentage of samples attributed to the method exceeded a dynamically adjusted threshold value. Method samples were periodically decayed to give more weight to recent samples. The controller dynamically adjusted this threshold value and the size of the sampling window in an attempt to reduce the overhead of processing the samples.
Later, significant algorithmic improvements in key data structures and additional performance tuning of the listeners, organizers, and controller reduced AOS overhead by two orders of magnitude. These overhead reductions obviate the need to filter events passed to the controller. This resulted in a more effective system with fewer parameters to tune and a sounder theoretical basis. In general, as we gained experience with the adaptive system implementation, we strove to reduce the number of tuning parameters. We believe that the closer the implementation matches the basic theoretical cost-benefit model, the more likely it will perform well and make reasonable and understandable decisions.
Profile-Directed Inlining Profile-directed inlining attempts to identify frequently traversed call graph edges, which represent caller-callee relationships, and determine whether it is beneficial to recompile the caller methods to allow inlining of the callee methods. In Jikes RVM, profile-directed inlining augments a number of static inlining heuristics. The role of profile-directed inlining is to identify high cost-high benefit inlining opportunities that evade the static heuristics and to predict the likely target(s) of invokevirtual and invokeinterface calls that could not be statically bound at compile time.
To accomplish this goal, the system takes a statistical sample of the method calls in the running application and maintains an approximation of the dynamic call graph based on this data. The system installs a listener that samples call edges whenever a yieldpoint is taken in the prologue or epilogue of a method. To sample the call edge, it records the compiled method id of the caller and callee methods and the offset of the call instruction in the caller’s machine code into a buffer. When the buffer of samples is full, the sampling window ends. The listener then unregisters itself (stops taking samples) and wakes an organizer to update the dynamic call graph with the new profile data. The optimizing compiler’s Inline Oracle uses the dynamic call graph to guide it’s inline decisions.
The system currently used is based on Arnold & Grove’s CGO 2005 paper. More details of the sampling scheme and the inlining oracle can be found there, or in the source code.
12.1 AOS Controller
A primary design goal for the adaptive optimization system is to enable research in online feedback-directed optimization. Therefore, we require the controller implementation to be flexible and extensible. As we gained experience with the system, the controller component went through several major redesigns to better support our goals.
The controller is a single Java thread that runs an infinite event loop. After initializing AOS, the controller enters the event loop and attempts to dequeue an event. If no event is available, the dequeue operation blocks (suspending the controller thread) until an event is available. All controller events implement an interface with a single method: process. Thus, after successfully dequeuing an event the controller thread simply invokes its process method and then, the work for that event having been completed, returns to the top of the event loop and attempts to dequeue another event. This design makes it easy to add new kinds of events to the system (and thus, extend the controller’s behavior), as all of the logic to process an event is defined by the event’s process method, not in the code of the controller thread.
A further level of abstraction is accomplished by representing the recompilation strategy as an abstract class with several subclasses. The process method of a hot method event invokes methods of the recompilation strategy to determine whether or not a method should be recompiled, and if so at what optimization level. The cost-benefit model itself is also reified in a class hierarchy of models to enable extension and variation. This set of abstractions enable a single controller implementation to execute a variety of strategies.
Another useful mechanism for experimentation is the ability to easily change the input parameters to AOS that define the expected compilation rates and execution speed of compiled code for the various compilers. By varying these parameters, one can easily cause the default multi-level cost-benefit model to simulate a single-level model (by defining all but one optimization level to be unprofitable). One can also explore other aspects of the system, for example the sensitivity of the model to the accuracy of these parameters. We found this capability to be so useful that the system supports a command line argument (-X:aos:dna=<filename>) that causes it to optionally read these parameters from a file.
12.2 Cost Benefit Model
The Jikes RVM Adaptive Optimization System attempts to evaluate the break-even point for each action using an online competitive algorithm. It relies on an analytic model to estimate the costs and benefits of each selective recompilation action, and evaluates the best actions according to the model predictions online.
A key advantage of this approach is that it allows a designer to extend the simple ”break-even” cost-benefit model to account for more sophisticated adaptive policies, such as selective compilation with multiple optimization levels, on-stack-replacement, and long-running analyses.
In general, each potential action will incur some cost and may confer some benefit. For example, recompiling a method will certainly consume some CPU cycles, but could speed up the program execution by generating better code. In this discussion we focus on costs and benefits defined in terms of time (CPU cycles). However, in general, the controller could consider other measures of cost and benefit, such as memory footprint, garbage allocated, or locality disrupted.
The controller will take some action when it estimates the benefit to exceed the cost. More precisely, when the controller wakes at time t, it considers a set of n available actions, the set A = {A1,A2,...,An}. For any subset S in P(A), the controller can estimate the cost C(S) and benefit B(S) of performing all actions Ai in S. The controller will attempt to choose the subset S that maximizes B(S) − C(S). Obviously S = {} has B(S) = C(S) = 0; the controller takes no action if it cannot find a profitable course.
In practice, the precise cost and benefit of each action cannot be known; so, the controller must rely on estimates to make decisions.
The basic model the controller uses to decide which method to recompile, at which optimization level, and at what time is as follows.
Suppose that when the controller wakes at time t, and each method m is currently optimized at optimization level mi,0 ≤ i ≤ k. Let M be the set of loaded methods in the program. Let Ajm be the action ”recompile method m at optimization level j, or do nothing if j = i.”
The controller must choose an action for each m in M. The set of available actions is Actions = {Ajm|0 ≤ j ≤ k,m ∈ M}.
Each action has an estimated cost and benefit: C(Ajm), the cost of taking action Ajm, for 0 ≤ j ≤ k and T(Ajm), the expected time the program will spend executing method m in the future, if the controller takes action Ajm.
For S in Actions, define C(S) = ∑ s∈SC(s). Given S, for each m in M, define Aminm to be the action Ajm in S that minimizes T(Ajm). Then define T(S) = ∑ m∈MT(Aminm).
Using these estimated values, the controller chooses the set S that minimizes C(S) + T(S). Intuitively, for each method m, the controller chooses the recompilation level j that minimizes the expected future compilation time and running time of m.
It remains to define the functions C and T for each recompilation action. The basic model models the cost C of compiling a method m at level j as a linear function of the size of m. The linear function is determined by an offline experiment to fit constants to the model.
The basic model estimates that the speedup for any optimization level j is constant. The implementation determines the constant speedup factor for each optimization level offline, and uses the speedup to compute T for each method and optimization level.
We assume that if the program has run for time t, then the program will run for another t units, and then terminate. We further assume program behavior in the future will resemble program behavior in the past. Therefore, for each method we estimate that if no optimization action is performed T(Ajm) is equal to the time spent executing method m so far.
Let M = (m1,...,mk) be the k compiled methods. When the controller wakes at time t, each compiled method m has been sampled ∑ m times. Let δ be the sampling interval, measured in seconds. The controller estimates that method m has executed δ ∑ m seconds so far, and will execute for another δ ∑ m seconds in the future.
When driving recompilation based on sampling, the controller can limit its attention to the set of methods that were sampled in the previous sampling interval. This optimization does not lose precision; if the number of samples associated with a method has not changed, then the controller’s estimate of the method’s future execution time will not change. This implies that if the controller were to consider a method that does not appear in the previous sampling interval, the controller would make exactly the same decision it did the last time it considered the method. This optimization, limiting the number of methods the controller must examine in each sampling interval, greatly reduces the amount of work performed by the controller.
Suppose the controller recompiles method m from optimization level i to optimization level j after having seen ∑ m samples. Let Si and Sjbe the speedup ratios for optimization levels i and j, respectively. After optimizing at level j, we adjust the sample data to represent the system state as if it had executed method m at optimization level j since program startup. So, we set the new number of samples for m to be ∑ m ⋅ (Si∕Sj). Thus to compute the time spent in m, we need know only one number, the ”effective” number of samples.
12.3 Jikes RVM’s compilers
Jikes RVM invokes a compiler for one of three reasons. First, when the executing code reaches an unresolved reference, causing a new class to be loaded, the class loader invokes a compiler to compile the class initializer (if one exists). Second, the system compiles each method the first time it is invoked. In these first two scenarios, the initiating application thread stalls until compilation completes.
In the third scenario, the adaptive optimization system can invoke a compiler when profiling data suggests that recompiling a method with additional optimizations may be beneficial. The system supports both background and foreground recompilation. With background recompilation (the default), a dedicated thread asynchronously performs all recompilations. With foreground configuration, the system invalidates a compiled method, thus, forcing recompilation at the desired optimization level at the next invocation (stalling the invoking thread until compilation completes).
The system includes two compilers with different tradeoffs between compilation overhead and code quality.
- The goal of the baseline compiler is to generate correct code quickly. For example, the IA32 baseline compiler translates bytecodes directly into native code by simulating Java’s operand stack. It does not build an intermediate representation and does not perform register allocation, resulting in native code that executes only somewhat faster than bytecode interpretation. However, it does achieve its goal of producing this code quickly, which significantly reduces the initial overhead associated with dynamic compilation.
- The optimizing compiler translates bytecodes into an intermediate
representation, upon which it performs a variety of optimizations. All
optimization levels include linear scan register allocation and BURS-based
instruction selection. The compiler’s optimizations are grouped into several
levels:
- Level 0 consists of a set of flow-sensitive optimizations performed on-the-fly during the translation from bytecodes to the intermediate representation and some additional optimizations that are either highly effective or have negligible compilation costs. The compiler performs the following optimizations during IR generation: constant, type, non-null, and copy propagation, constant folding and arithmetic simplification, branch optimizations, field analysis, unreachable code elimination, inlining of trivial methods (A trivial method is one whose body is estimated to take less code space than 2 times the size of a calling sequence and that can be inlined without an explicit guard.), elimination of redundant nullchecks, checkcasts, and array store checks. As these optimizations reduce the size of the generated IR, performing them tends to reduce overall compilation time. Level 0 includes a number of cheap local (The scope of a local optimization is one extended basic block.) optimizations such as local redundancy elimination (common subexpression elimination, loads, and exception checks), copy propagation, constant propagation and folding. Level 0 also includes simple control flow optimizations such as static basic block splitting, peephole branch optimization, and tail recursion elimination. Finally, Level 0 performs simple code reordering, scalar replacement of aggregates and short arrays, and one pass of intraprocedural flow-insensitive copy propagation, constant propagation, and dead assignment elimination.
- Level 1 resembles Level 0, but significantly increases the aggressiveness of inlining heuristics. The compiler performs both unguarded inlining of final and static methods and (speculative) guarded inlining of non-final virtual and interface methods. Speculative inlining is driven both by class hierarchy analysis and online profile data gathered by the adaptive system. In addition, the compiler exploits “preexistence” to safely perform unguarded inlining of some invocations of non-final virtual methods without requiring stack frame rewriting on invalidation. It also runs multiple passes of some of the Level 0 optimizations and uses a more sophisticated code reordering algorithm due to Pettis and Hansen.
- Level 2 augments level 1 with loop optimizations such as normalization and unrolling; scalar SSA-based flow-sensitive optimizations based on dataflow, global value numbering, global common subexpression elimination, redundant and conditional branch elimination; and heap array SSA-based optimizations, such as load/store elimination, and global code placement. NOTE: many of the O2 optimizations are disabled by default by defining them as O3 optimizations because they are believed to be somewhat buggy.
The adaptive system uses information about average compilation rate and relative speed of compiled code produced by each compiler/optimization level to make its decisions. These characteristics of the compilers are the key inputs to enable selective optimization to be effective. It allows one to employ a quick executing compiler for infrequently executed methods and an optimizing compiler for the most critical methods. See org.jikesrvm.adaptive.recompilation.CompilerDNA for the current values of these input parameters to the adaptive systems cost/benefit model.
12.4 Life Cycle of a Compiled Method
In early implementations of Jikes RVM’s adaptive system, compilation required holding a global lock that serialized compilation and also prevented classloading from occurring concurrently with compilation. This bottleneck was removed in version 2.1.0 by switching to a finer-grained locking discipline to coordinate compilation, speculative optimization, and class loading. Since no published description of this locking protocol exists outside of the source code, we briefly summarize the life cycle of a compiled method here.
When Jikes RVM compiles a method, it creates a compiled method object to represent this particular compilation of the source method. A compiled method has a unique id, and stores the compiled code and associated compiler meta-data. After a brief initialization phase, the compiled method transitions from uncompiled to compiling when compilation begins. During compilation, the optimizing compiler may perform speculative optimizations that can be invalidated by future class loading. Each time the compiler so speculates, it records a relevant entry in an invalidation database. Upon finishing compilation, the system checks to ensure that the current compilation has not already been invalidated by concurrent classloading. If it has not, then the system installs the compiled code, and subsequent invocations will branch to the newly created code.
Each time a class is loaded, the system checks the invalidation database to identify the set of compiled methods to mark as obsolete, because this classloading action invalidates speculative optimizations previously applied to that method. A method may transition from either compiling or installed to obsolete due to a classloading-induced invalidation. A method can also transition from installed to obsolete when the adaptive system selects a method for optimizing recompilation and a new compiled method is installed to replace it.
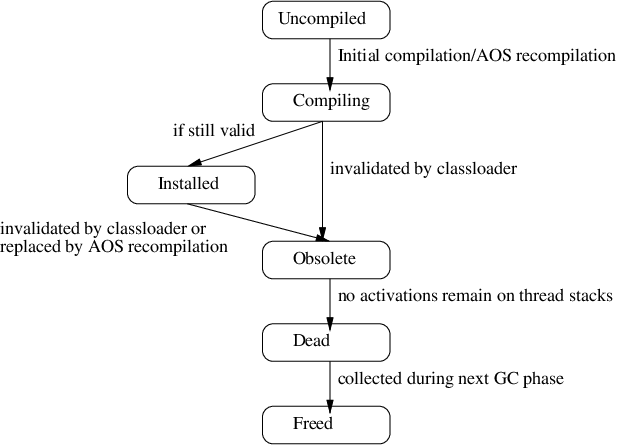
Once a method is marked obsolete, it will never be invoked again. However, before the generated code for the compiled method can be garbage collected, all existing invocations of the compiled method must be complete. A compiled method transitions from obsolete to dead when no invocations of it exist on any thread stack. Jikes RVM detects this as part of the stack scanning phase of garbage collection; as stack frames are scanned, their compiled methods are marked as active. Any obsolete method that is not marked as active when stack scanning completes is marked as dead and the reference to it is removed from the compiled method table. It will then be freed during the next garbage collection.
12.5 Logging and Debugging
Complex non-deterministic systems such as the Jikes RVM adaptive system present challenges for system understanding and debugging. Virtually all of the profiling data collected by the runtime measurements component results from non-deterministic timer-based sampling at taken yieldpoints. The exact timing of these interrupts, and thus, the profile data that drives recompilation decisions, differs somewhat each time an application executes. Furthermore, many of the optimizations in the optimizing compiler rely on online profiles of conditional branch probabilities, i.e., the probabilities at the point in an execution when the recompilation occurs. Thus, because recompilations can occur at different times during each execution, a method compiled at the same optimization level could be compiled slightly differently on different runs.
The primary mechanism we use to manage this complexity is a record-replay facility for the adaptive system, where online profile data is gathered during one run and used in a subsequent run. More specifically, as methods are dynamically compiled, the system can record this information into a log file. At the end of the run, the system can optionally dump the branch probabilities of all instrumented conditional branches, the profile-derived call graph, and the profile-directed inlining decisions. This log of methods and the files of profile data can then be provided as inputs to a driver program (org.jikesrvm.tools.opt.OptTestHarness) that can replay the series of compilation actions, and then optionally execute the program. Usually a fairly rapid binary search of methods being compiled and/or the supporting profile data suffices to narrow the cause of a crash to a small set of actions taken by the optimizing compiler. Although this does not enable a perfectly accurate replay of a previous run, in practice, we have found that it suffices to reproduce almost all crashes caused by bugs in the optimizing compiler.
In addition to this record-replay mechanism, which mainly helps debugging the optimizing compiler, the adaptive system can generate a log file that contains detailed information about the actions of its organizer and controller threads. A sample is shown below:
90:..7136817287 Controller notified that read(14402) has 4.0 samples
92:..7139813016 Doing nothing cost (leaving at baseline) to read is 40.0
92:..7139830219 Compiling read cost at O0=40.42, future time=49.81
92:..7139842466 Compiling read cost at O1=65.99, future time=72.58
92:..7139854029 Compiling read cost at O2=207.44, future time=213.49
110:..7166901172 Controller notified that read(14402) has 9.0 samples
111:..7168378722 Doing nothing cost (leaving at baseline) to read=90.0
111:..7168396493 Compiling read cost at O0=40.42, future time=61.54
111:..7168409562 Compiling read cost at O1=65.99, future time=80.81
111:..7168421097 Compiling read cost at O2=207.44, future time=221.06
111:..7168435937 Scheduling level 0 recompilation of read (priority=28.46)
112:..7169879779 Recompiling (at level 0) read
114:..7173293360 Recompiled (at level 0) read
150:..7227058078 Controller notified that read(14612) has 5.11 samples
151:..7228691160 Doing nothing cost (leaving at O0) to read=51.12
151:..7228705466 Compiling read cost at O1=66.26, future time=102.14
151:..7228717124 Compiling read cost at O2=208.29, future time=241.24
<....many similar entries....>
998:..8599006259 Controller notified that read(14612) has 19.11 samples
999:..8599561634 Doing nothing cost (leaving at O0) to read=191.13
999:..8599576368 Compiling read cost at O1=54.38, future time=188.52
999:..8599587767 Compiling read cost at O2=170.97, future time=294.14
999:..8599603986 Scheduling level 1 recompilation of read (priority=2.61)
1000:..8601308856 Recompiling (at level 1) read
1002:..8604580406 Recompiled (at level 1) read
1018:..8628022176 Controller notified that read(15312) has 18.41 samples
1019:..8629548221 Doing nothing cost (leaving at O1) to read=184.14
1019:..8629563130 Compiling read cost at O2=170.97, future time=340.06
This sample shows an abbreviated subset of the log entries associated with the method read of the class spec.benchmarks._213_javac.ScannerInputStream, one of the hotter methods of the SPECjvm98 benchmark _213_javac. The first pair of numbers are the controller clock (number of timer interrupts since execution began) and the value of the hardware cycle counter (Time.cycles()) for the log entry. These log entries show the cost-benefit values computed by the controller for various possible optimization actions and the progression of the method from baseline compilation through two recompilations (level 0 and then at level 1). For example, at time 92, we see four entries that give the estimated total future time (the sum of the compilation cost and the total future execution time in a method) for performing no recompilation and for each optimization level. Because the total future time for not recompiling (40) is less than the other alternatives (49.81, 72.58, and 213.49), the method is not scheduled for recompilation. However, at time 110, the method has been sampled more often. Thus, the total future time estimate is updated, resulting in two recompilation actions (level 0 and level 1) that are more attractive than taking no recompilation action. Because level 0 gives the least future time, this decision is chosen by placing a recompilation event in the recompilation priority queue. The priority for the event is the expected improvement of performing this recompilation, i.e., the difference between the future time for the new level and the future time for current execution (90 − 61.54 = 28.46).
At clock time 150 a similar pattern occurs when considering whether to recompile this method at level 1 or 2; initially recompiling at higher levels is not chosen (clock time 151) until sufficient samples of the method have occurred (clock time 999).
The figure also illustrates how samples of a method at lower optimization level are incorporated into the total samples for a method that has been recompiled. The samples at the lower level are scaled by the relative speed of the two levels as defined by the CompilerDNA, and used as the initial number of samples for the higher level. For example, at clock time 100, the baseline compiled version of the method has 9 samples. When the method is recompiled at level 0, these methods are scaled down by 4.26, which is the expected speedup defined by the CompilerDNA for going from baseline to level 0, resulting in a value of 2.11. At clock time 160, the level 0 version of method has 5.11 samples, i.e, 3 additional samples of the method have occurred.
12.6 Threading and Yieldpoints
Jikes RVM creates a native thread for each Java thread that is started. Each compiler generates yield points, which are program points where the running thread checks to determine if it should yield to another thread. The compilers insert yield points in method prologues, method epilogues, and on loop backedges.
The adaptive optimization system piggybacks on this yieldpoint mechanism to gather profile data. The thread scheduler provides an extension point by which the runtime measurments component can install listeners that execute each time a yieldpoint is taken. Such listeners primarily serve to sample program execution to identify frequently-executed methods and call edges. Because these samples occur at well-known locations (prologues, epilogues, and loop backedges), the listener can easily attribute each sample to the appropriate Java source method.
The Jikes RVM implementation introduces a weakness with this mechanism, in that samples can only occur in regions of code that have yieldpoints. Some low-level Jikes RVM subsystems, such as the thread scheduler and the garbage collector, elide yieldpoints because those regions of code rely on delicate state invariants that preclude thread switching. These uninterruptible regions can distort sampling accuracy by artificially inflating the probability of sampling the first yieldpoint executed after the program leaves an uninterruptible region of code.